
Yisheng Zhou | Software Engineer II Liang Mou | Sr Staff Software Engineer Gabriel Raphael Garcia Montoya | Staff Software Engineer Istvan Podor | Staff Software Engineer Introduction In the first post of this series , we introduced Pinterest’s next-generation CDC-based ingestion platform built on Kafka, Flink, Spark, and Iceberg. In production, upstream schemas are constantly evolving, and in a…
#spark
3 posts
24 Jun
24 Jan 2025
Much of our heatmaps are built on batch data outputs stored in Rain At Strava, we love maps — some of our most loved features are nestled on map surfaces. My team, the Geo team, is focused on building and improving these products. On the Geo and Metro teams, we tend to work with large datasets: aggregations of open source…
29 Oct 2021
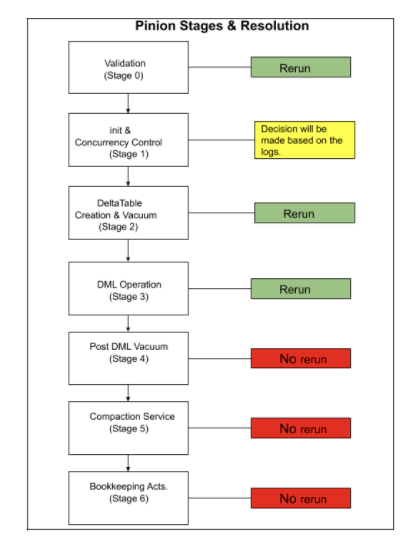
Pinion — The Load Framework Part-2 This post is the 2nd part of the “Pinion — The Load Framework” series. In case you have not read the 1st post, you can read it here . In this post, we are going to cover the following topics. How does Pinion use Delta Lake for SCD operations? Small file problem with Delta…