Last year, SoundCloud upgraded its AAC encoder for the first time in over a decade. The new one (Fraunhofer’s libfdk_aac) delivers higher…
#streaming
8 posts
18 Jun
Last year, SoundCloud upgraded its AAC encoder for the first time in over a decade. The new one (Fraunhofer’s libfdk_aac) delivers higher…
10 Jun

From foundational ETL and analytics to the frontier of generative AI, Apache Spark serves as the architectural backbone for global data processing. However, as data volumes scale, the trade-off between performance and infrastructure costs can be a limiting factor for growth. In the agentic era, where autonomous agents can trigger thousands of concurrent, multi-hop queries, this performance bottleneck directly dictates…
4 Jun

At Google Cloud, our goal is to let you run large-scale analytical and data science workloads with maximum efficiency so you can process big data pipelines, machine learning, and ETL tasks. We recently announced that the Dataproc service is now Managed Service for Apache Spark, reflecting our deep integration with the Agentic Data Cloud. To support the diverse architectural needs…
3 Jun
Whether you use it for data preparation, real-time interactive queries, AI model training, or something entirely different, running Apache Spark at scale is demanding — you shouldn’t have to manage the underlying infrastructure too. Late last year, we announced the general availability (GA) of our serverless Managed Service for Apache Spark runtime version 3.0, prioritizing speed, simplicity, and reliability. Since…
2 Jun
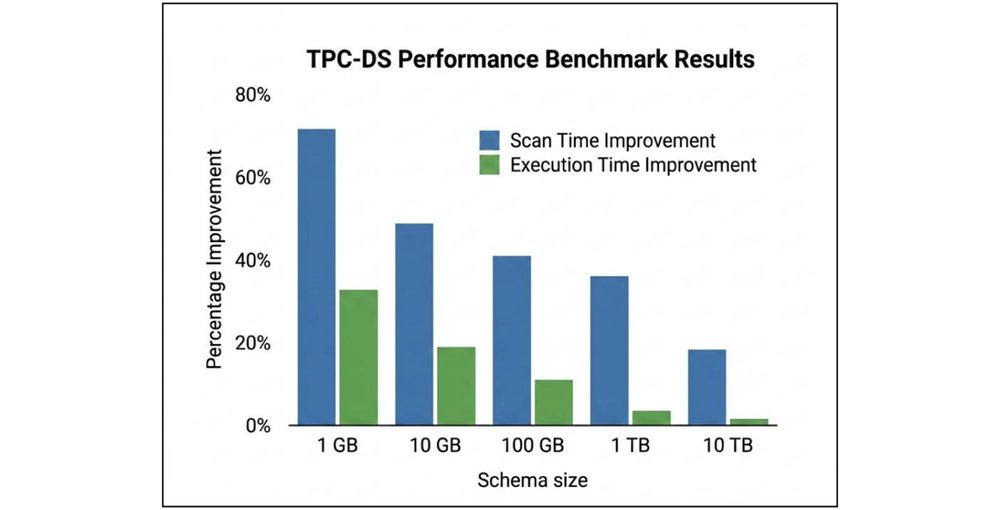
Many data engineers spend significant time managing compatibility and getting best performance across multiple analytics engines. To help solve this pain point, we are excited to announce gcs-analytics-core, a new open-source Java library designed to centralize and accelerate analytics optimizations for Google Cloud Storage (GCS). With this, you get the flexibility to select your preferred analytics engine while achieving high…
15 Sept 2025
At SoundCloud, we’re always looking for ways to improve the listening experience for our creators, partners, and listeners. One of the…
3 May 2019
Maestro is a library we have developed to handle all playback across SoundCloud web applications. It successfully handles tens of millions of plays per day across soundcloud.com, our mobile site, our widget, Chromecast, and our Xbox application. We are considering open sourcing it, and this blog post is a technical overview of what we’ve achieved thus far with Maestro.