
Expedia Group Technology — Innovation Using large language models to reveal bottlenecks in Spark SQL execution plans Photo by Luis del Río If you’ve ever stared at a 300-plus-node physical plan at 2 a.m. trying to spot a missing broadcast or one cursed skewed partition, this is for you. Spark makes it deceptively easy to write complex SQL that looks…
#big-data
23 posts
30 Jun
19 Jun
By Amer Hesson , Marcelo Mayworm , James Mulcahy , and Brittany Truong The Problem: Managing Assets at Netflix Scale Netflix’s Data Platform is vast. We have millions of tables in our data warehouse and tens of thousands of scheduled workloads running across our orchestration systems. Behind each of these assets sits an engineer, a team, or an initiative —…
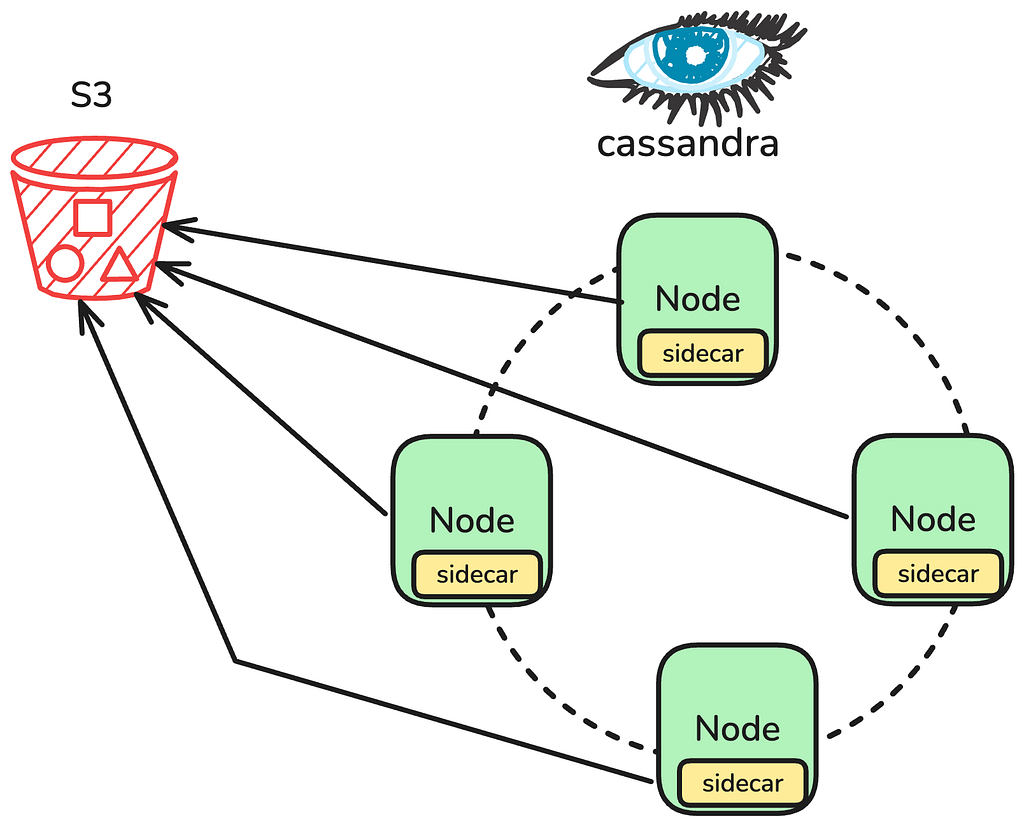
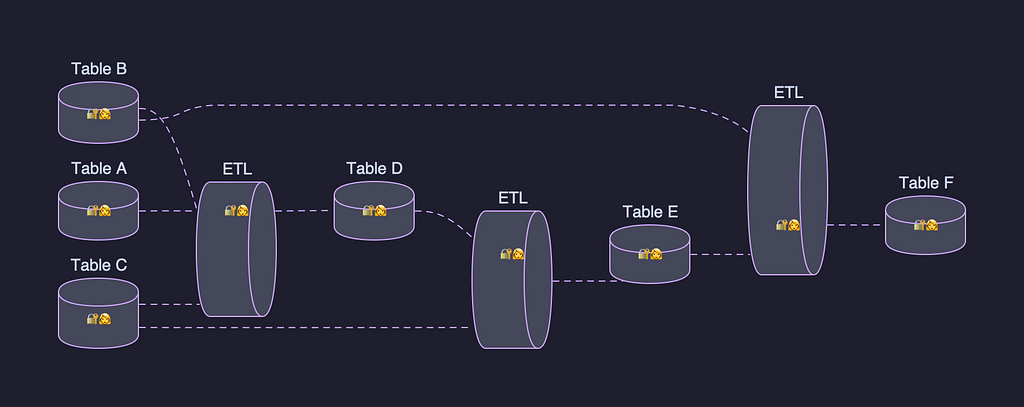
By Guil Pires , Jennifer Prince , Jose Camacho , Ken Kurzweil , Phanindra Chunduru Background In a previous post, we introduced Data Bridge , a unified management plane for batch Data Movement at Netflix. Historically, several bespoke Data Movement connectors were developed across different engineering organizations to fulfill their specific requirements. Over the last few years, the Data Movement…
29 May
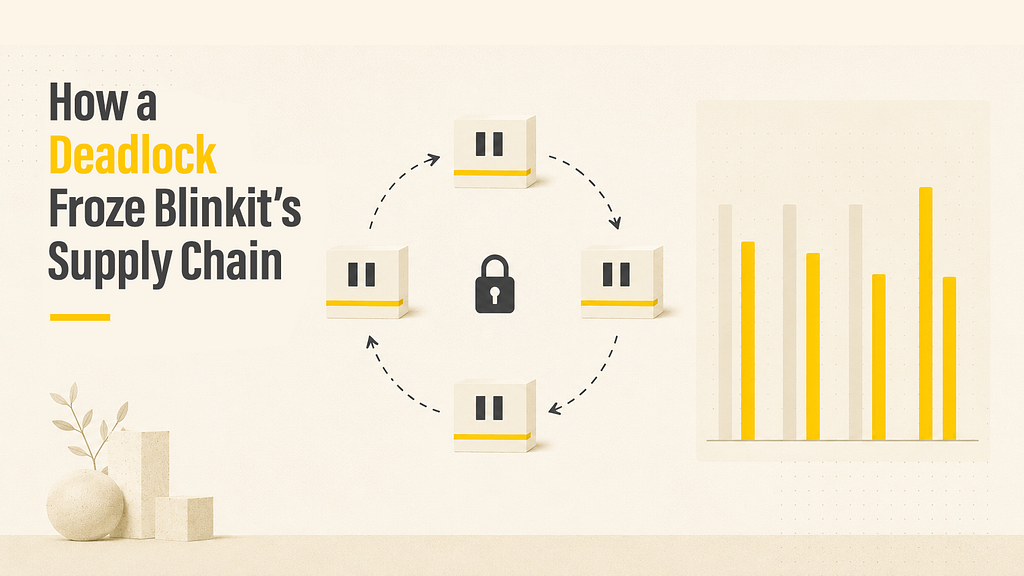
A silent deadlock in our query engine was stalling inventory replenishment jobs with no error, no crash — just infinite waiting. This is the story of how we found it, traced it to an open-source bug, and fixed it upstream. TL;DR Trino’s Hudi connector used a single thread pool for both producing file splits and signalling when there was room…
5 May
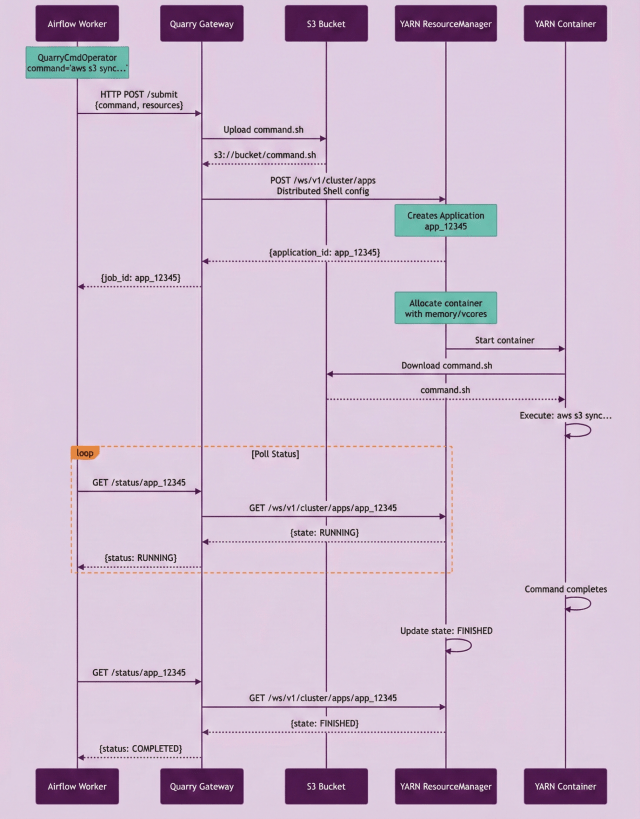
Excerpt By 2024, Slack’s data platform had accumulated 700+ SSH-based operators orchestrating critical data pipelines. We’re talking daily search indexing that processed terabytes of data, analytics jobs powering business intelligence, the whole shebang. Every single one of these jobs required direct SSH access to production AWS Elastic MapReduce (EMR) clusters. We had a massive security…
9 Dec 2025
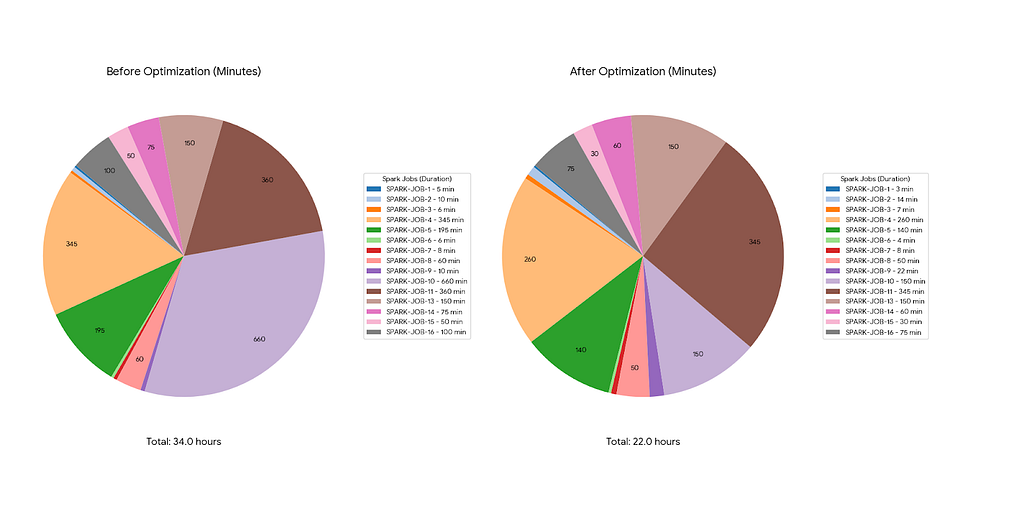
Context Ambitious goal and the scope of the problem We were chasing a critical, futuristic business requirement for our big data pipelines achieving “1-day planning,” defined as a total execution window of 24 hours or less . The entire process is extensive, processing a 7TB data volume each cycle across 19 distinct plans (16 Spark pipelines and 3 Data Science…
6 Oct 2025

As a data engineer, I used to see metrics as just numbers on a dashboard — until I realized they’re the lens through which customers view and run their operations. In customer support, for example, agent productivity metrics aren’t just figures, they’re actionable insights that drive efficiency, shape staffing decisions, and directly impact customer satisfaction. These aren’t just charts —…
2 Jul 2024

Unlocking Efficiency and Performance: Navigating the Spark 3 and EMR 6 Upgrade Journey at Slack
SlackSlack Data Engineering recently underwent data workload migration from AWS EMR 5 (Spark 2/Hive 2 processing engine) to EMR 6 (Spark 3 processing engine). In this blog, we will share our migration journey, challenges, and the performance gains we observed in the process. This blog aims to assist Data Engineers, Data Infrastructure Engineers, and Product…
21 Feb 2024

Leveraging Spark 3 and NVIDIA’s GPUs to Reduce Cloud Cost by up to 70% for Big Data Pipelines
PaypalBy Ilay Chen and Tomer Akirav At PayPal, hundreds of thousands of Apache Spark jobs run on an hourly basis, processing petabytes of data and requiring a high volume of resources. To handle the growth of machine learning solutions, PayPal requires scalable environments, cost awareness and constant innovation. This blog explains how Apache Spark 3 and GPUs can help enterprises…
31 Aug 2023

On the racetrack of building ML applications, traditional software development steps are often overtaken. Welcome to the world of MLOps, where unique challenges meet innovative solutions and consistency is king. At Bazaarvoice, training pipelines serve as the backbone of our MLOps strategy. They underpin the reproducibility of our model builds. A glaring gap existed, however, […]
17 Aug 2021
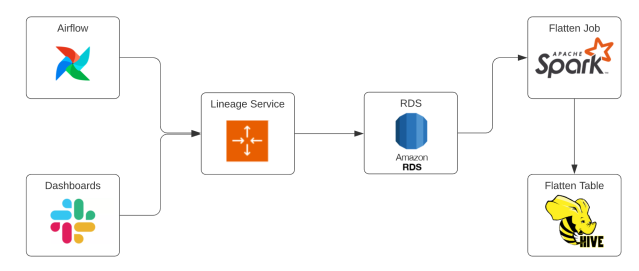
Reinventing how the world does work inevitably creates a lot of data. Each year, Slack’s scale has increased and the volume of data ingested and stored has kept pace. To make it possible to understand relationships within our data, we’ve invested heavily in an automated data lineage framework. This facilitates producer/consumer coordination, improves risk mitigation,…
16 Nov 2020
My thoughts and take homes after using Kedro for 6 months in various projects and teams.
7 Aug 2019
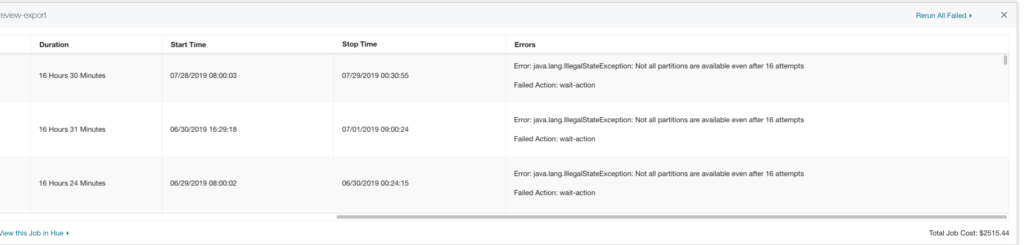
Parth Shah and Thai Bui Overview One of the reasons why Hadoop jobs are hard to operate is their inability to provide clear, actionable error diagnostic messages for users. This stems from the fact that Hadoop consists of many interrelated components. When a component fails or behaves poorly, the failure will be cascaded to its […]
2 Jan 2018
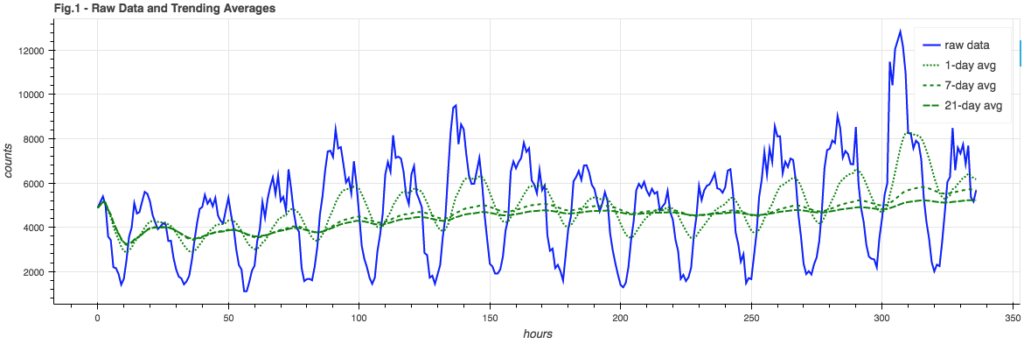
Recently, during a holiday lull, I decided to look at another way of modeling event stream data (for the purposes of anomaly detection). I’ve dabbled with (simplistic) event stream models before but this time I decided to take a deeper look at Twitter’s anomaly detection algorithm [1], which in turn is based (more or less) […]
21 Jun 2016
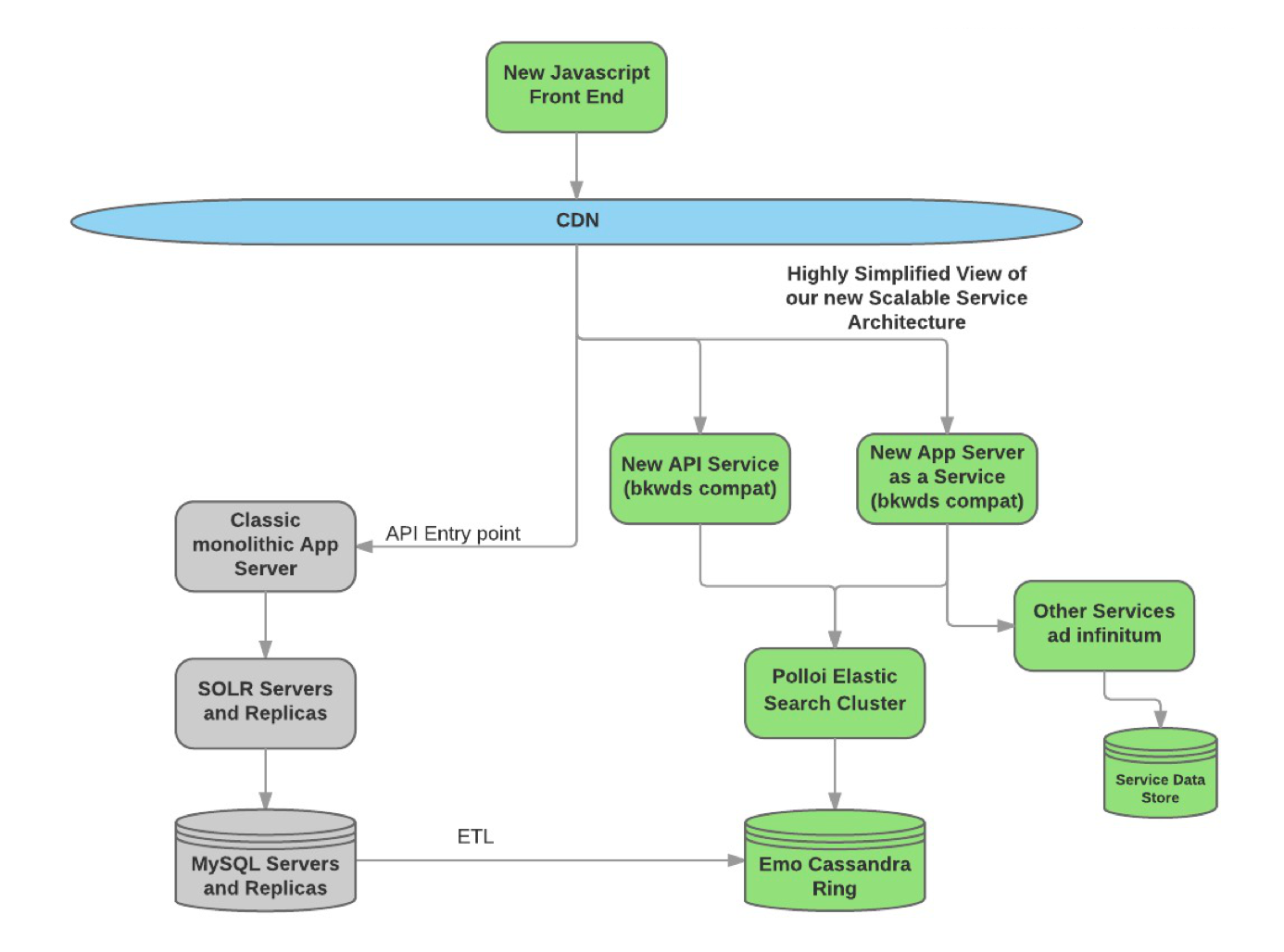
Divide and Conquer As Engineers, we often like nice clean solutions that don’t carry along what we like to call technical debt. Technical debt literally is stuff that we have to go back to fix/rewrite later or that requires significant ongoing maintenance effort. In a perfect world, we fire up the the new platform and […]
10 Jun 2016
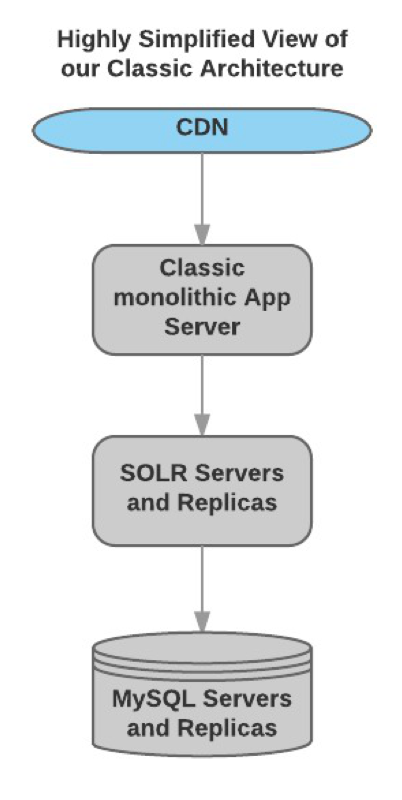
At Bazaarvoice, we’ve pulled off an incredible feat, one that is such an enormous task that I’ve seen other companies hesitate to take on. We’ve learned a lot along the way and I wanted to share some of these experiences and lessons in hopes they may benefit others facing similar decisions. The Beginning Our original […]
1 Jun 2016
With Java 8 now in the mainstream, Scala and Clojure are no longer the only choices to develop readable, functional code for big data technology on the JVM. In this post we see how SoundCloud is leveraging Apache Crunch and the new Crunch Lambda module to do the high-volume data processing tasks which are essential at early stages in our…
24 Dec 2015
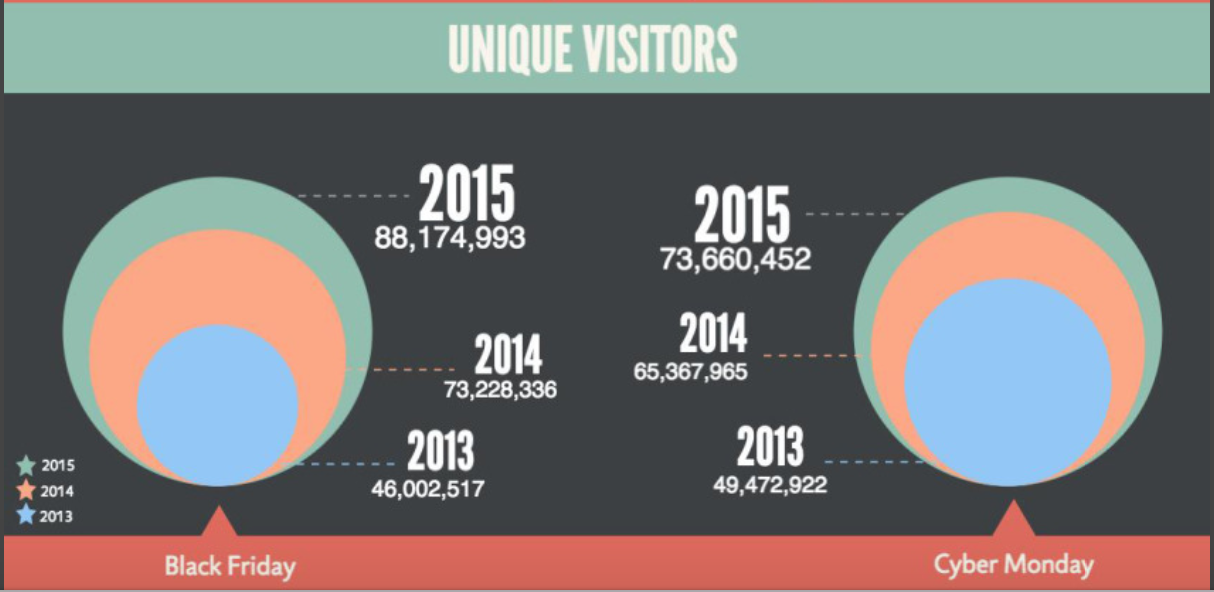
Preparing for the Holiday season is a year round task for all of us here at Bazaarvoice. This year we saw many retailers extending their seasonal in-store specials to their websites as well. We also saw retailers going as far as closing physical stores on Thanksgiving (Nordstrom, Costco, Home Depot, etc.) and Black Friday (REI). Regardless […]
4 Sept 2015
Every year Bazaarvoice R&D throws BVIO, an internal technical conference followed by a two-day hackathon. These conferences are an opportunity for us to focus on unlocking the power of our network, data, APIs, and platforms as well as have some fun in the process. We invite keynote speakers from within BV, from companies who use […]
23 Mar 2015
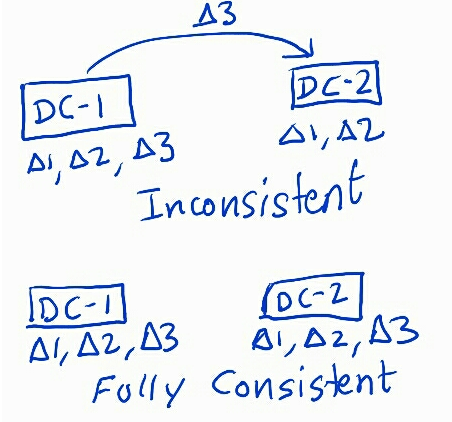
A distributed data system consisting of several nodes is said to be fully consistent when all nodes have the same state of the data they own. So, if record A is in State S on one node, then we know that it is in the same state in all its replicas and data centers. Full […]
20 Feb 2015
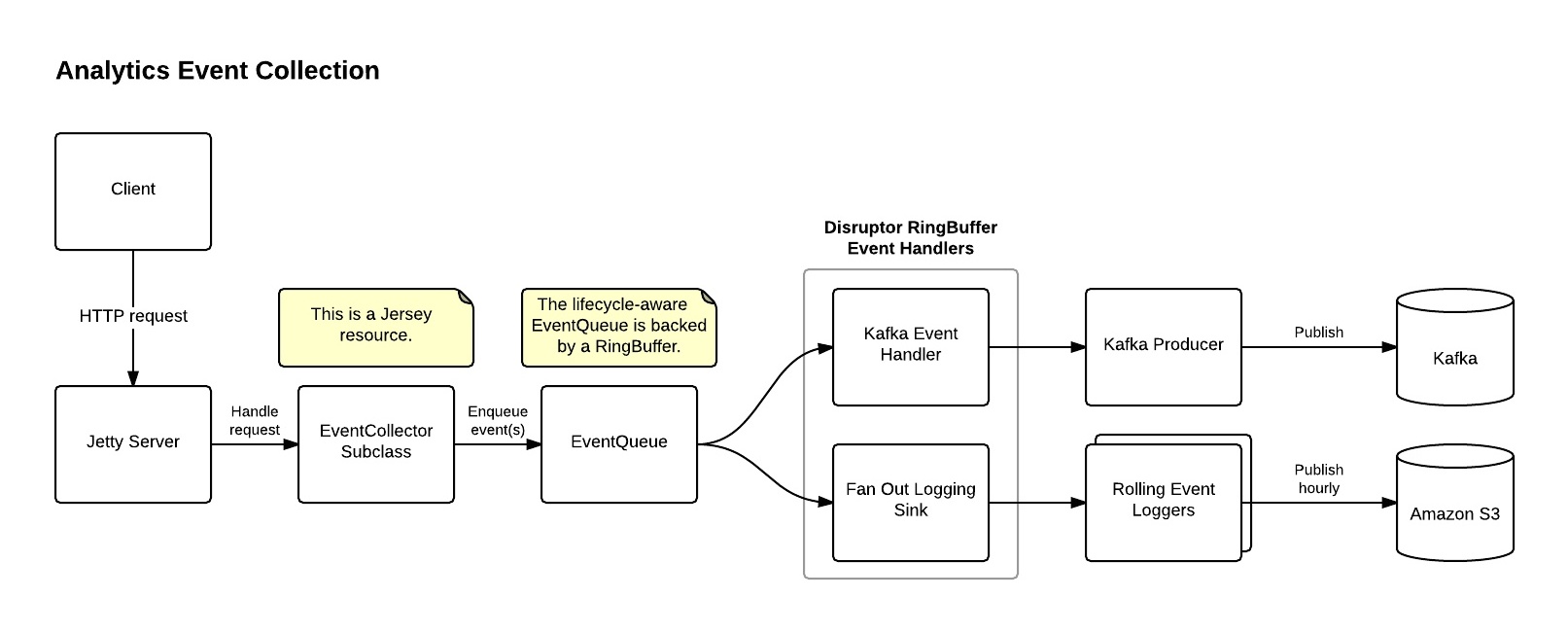
Every holiday season, the virtual doors of your favorite retailer are blown open by a torrent of shoppers who are eager to find the best deal, whether they’re looking for a Turbo Man action figure or a ludicrously discounted 4K flat screen. This series focuses on our Big Data analytics platform, which is used to learn more […]
21 Jun 2014
One for the weekend: Big Data Big Data pic.twitter.com/18VPE9LGDq — Victor Agreda Jr (@superpixels) June 19, 2014
28 Apr 2011
As SoundCloud rapidly grows our initial systems need an overhaul. Our scaling strategy has been very realistic, design for 10x our current…