Why Most Single Source of Truth Initiatives Fail (And What Successful Teams Do Differently)
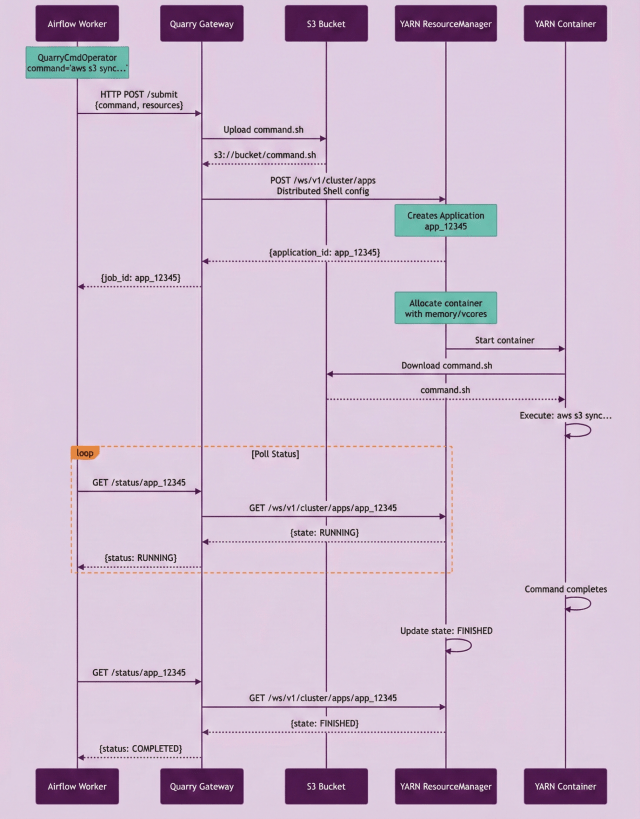
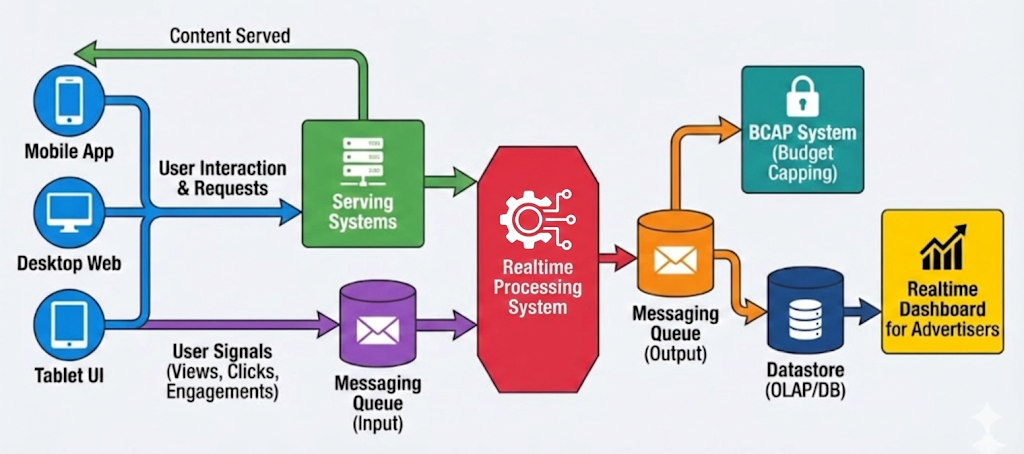
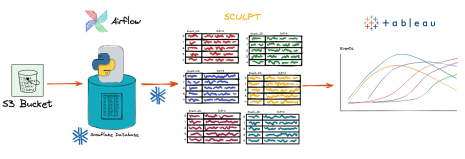
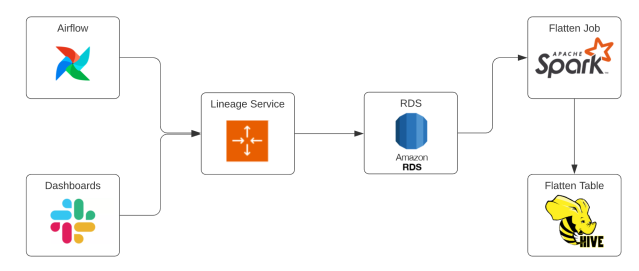
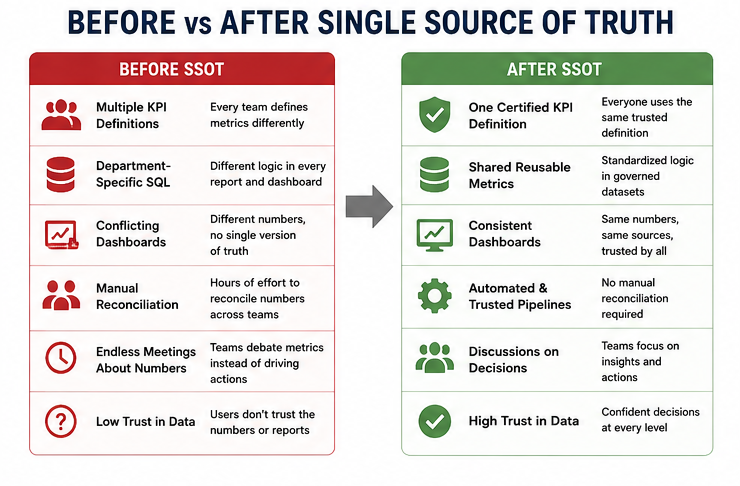
Housing.com“We have multiple dashboards showing different numbers. Which one is correct?” If you’ve worked in data long enough, you’ve probably heard this question more times than you’d like. Sales reports one revenue figure. Finance reports another. Product Analytics has a third. Executives spend more time debating whose dashboard is correct than discussing what action to take. The natural response is…