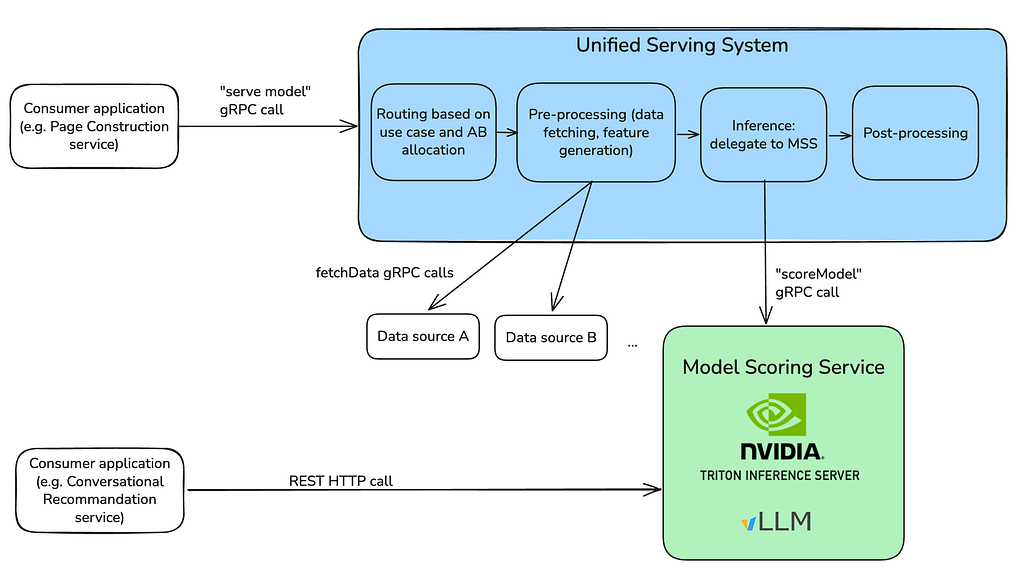
By AI Platform’s Model Runtime team and Inference team Introduction Most organizations consume LLMs through hosted APIs. Netflix went further — we run the full stack ourselves, from model deployment through inference, inside our existing production environment rather than a separate ML silo. Some of those decisions weren’t obvious, and a few revealed their trade-offs only under production load. This…
Netflix Technology Blog
https://netflixtechblog.com/ · 22 posts · history since 2026 · active
17 Jul
13 Jul

By Parth Jain , Rakesh Sukumar , Yingwu Zhao , Renzo Sanchez-Silva & Nathan Fisher A deep dive into the engineering challenges of building a real-time service dependency map at Netflix scale: from streaming architectures and distributed aggregation pipelines to time-travel queries and the methodology that made it work. Introduction In our first post , we introduced the problem: engineers…
29 Jun

Authors: Lequn Wang , J iangwei Pan , and Linas Baltrunas Figure 1. Autoregressive homepage generation. GenPage builds a Netflix homepage one row or entity at a time, each one conditioned on what’s already on the page and the user’s context. Introduction The Netflix homepage is the first thing users see when they open the app and the primary way…
23 Jun

By Zhuoning Yuan , Ta-Ying Cheng , Benjamin Klein , Bahareh Azarnoush Introduction At Netflix, we build technology to help storytellers bring their creative visions to life and to help members discover the stories they love. To connect stories with diverse audiences around the world, we produce promotional assets, including trailers, teasers, and social short‑form videos, that build on and…
22 Jun
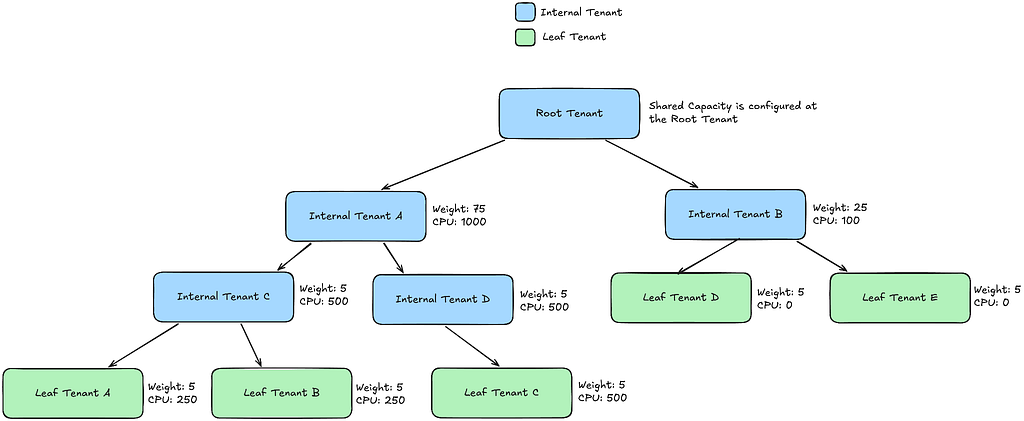
By Alvin Bao , Alex Petrov , Jennifer Lai , Aidan Sherr , and Samartha Chandrashekar As a part of the journey to transition Netflix’s compute infrastructure to be more Kubernetes-native, we have leaned into incorporating components from the Kubernetes ecosystem into our container platform Titus . One example of this is our use of Kueue , a cloud-native job…
19 Jun

By Celina Amados At Netflix, our catalog metadata is crucial to our member experience, and a single corrupted data state can impact millions of viewers immediately. To protect streaming reliability, we built an automated data canary system that validates data transformations using production traffic. This canary detects issues in under 10 minutes, and blocks bad data from reaching our members.…
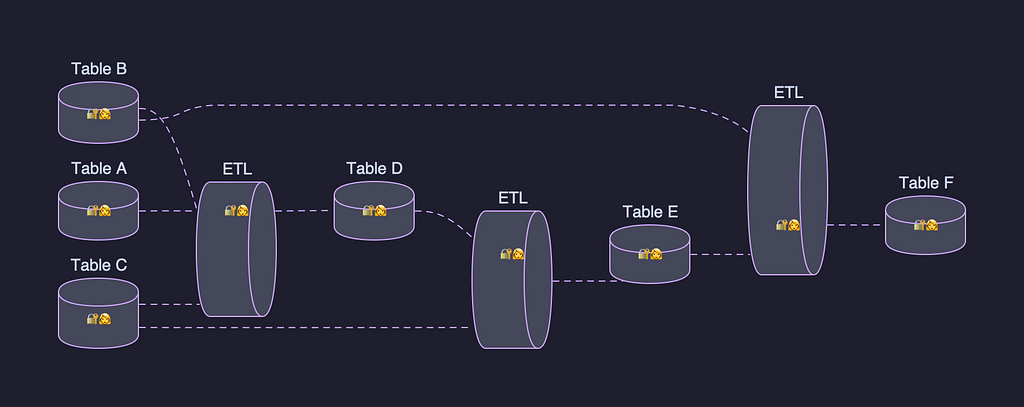
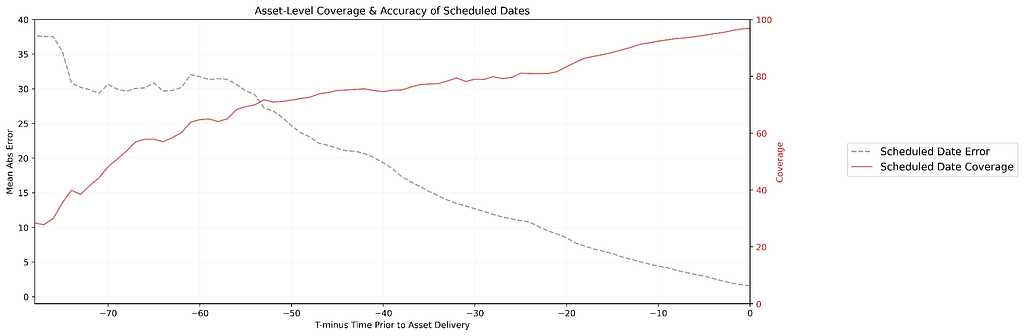
By Amer Hesson , Marcelo Mayworm , James Mulcahy , and Brittany Truong The Problem: Managing Assets at Netflix Scale Netflix’s Data Platform is vast. We have millions of tables in our data warehouse and tens of thousands of scheduled workloads running across our orchestration systems. Behind each of these assets sits an engineer, a team, or an initiative —…
by Emily Gill Each year, we bring the Analytics Engineering community together for an Analytics Summit — a multi-day internal conference to share analytical deliverables across Netflix, discuss analytic practice, and build relationships within the community. This post is one of several topics presented at the Summit highlighting the breadth and impact of Analytics work across different areas of the…
By Guil Pires , Jennifer Prince , Jose Camacho , Ken Kurzweil , Phanindra Chunduru Background In a previous post, we introduced Data Bridge , a unified management plane for batch Data Movement at Netflix. Historically, several bespoke Data Movement connectors were developed across different engineering organizations to fulfill their specific requirements. Over the last few years, the Data Movement…
by Matthew Wood , Ishan Gupta , Kevin Mercurio, Devon Bryant , and Claire Dorman In his seminal book “Thinking, Fast and Slow,” Daniel Kahneman describes two systems that drive human cognition: System 1, which operates automatically and quickly with little effort, and System 2, which allocates attention to more challenging mental activities requiring deliberate focus. This dual-process theory has…
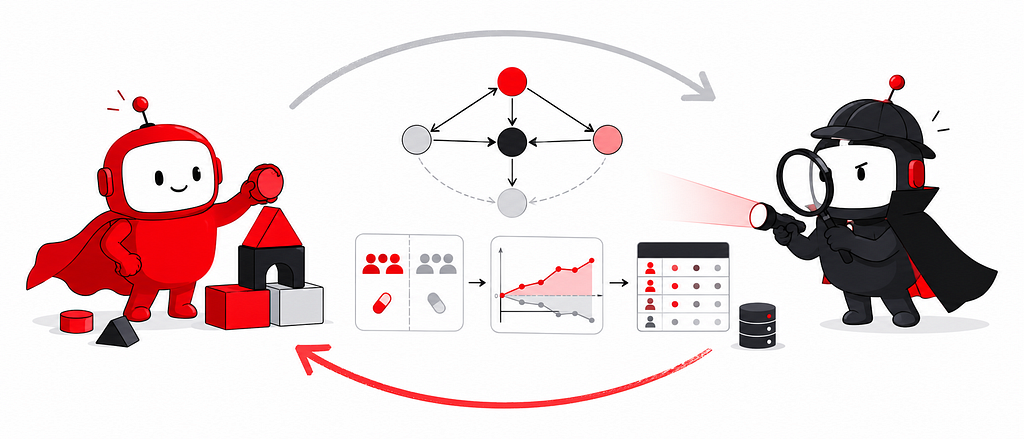
By Winston Chou, Adrien Alexandre, Lars Olds, Yi Zhang, Garrett Hagemann, and Nathan Kallus Introduction Imagine asking a data agent to analyze the causal relationship between two variables, such as the effect of watching a popular Netflix show on long-term member retention. It queries your data, runs a regression, and confidently returns an answer. How much should you trust it?…
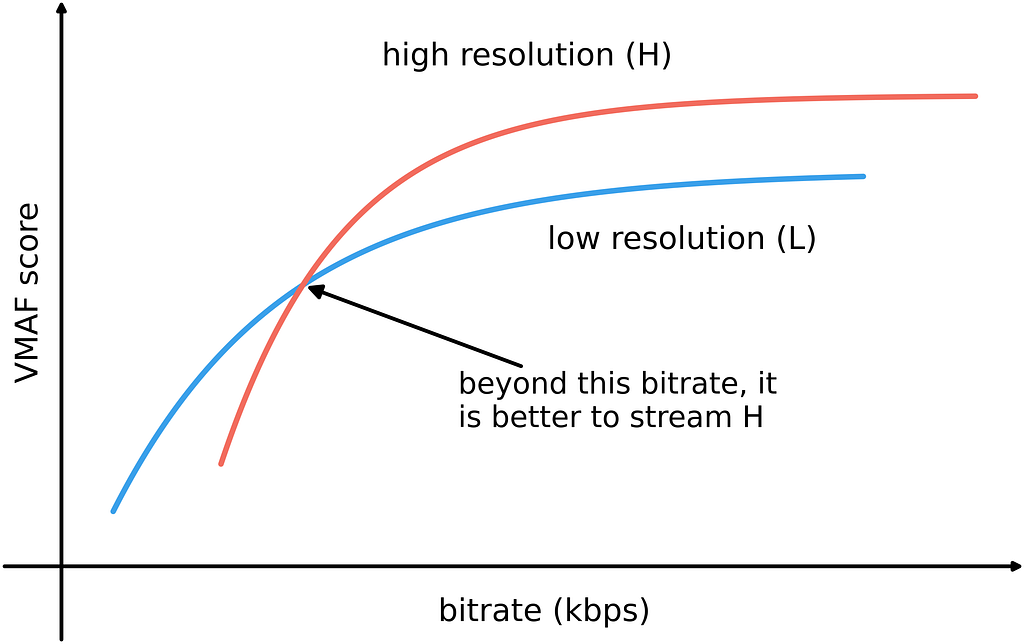
By Christos G. Bampis , Zhi Li , Kyle Swanson, Nil Fons Miret and Pavan Madhusudanarao Will this encode look good to Netflix members? Does switching to a new codec improve quality at the same bitrate and by how much? What is the best way to encode a movie title given a target bitrate budget? For years, VMAF has reliably…
3 Jun
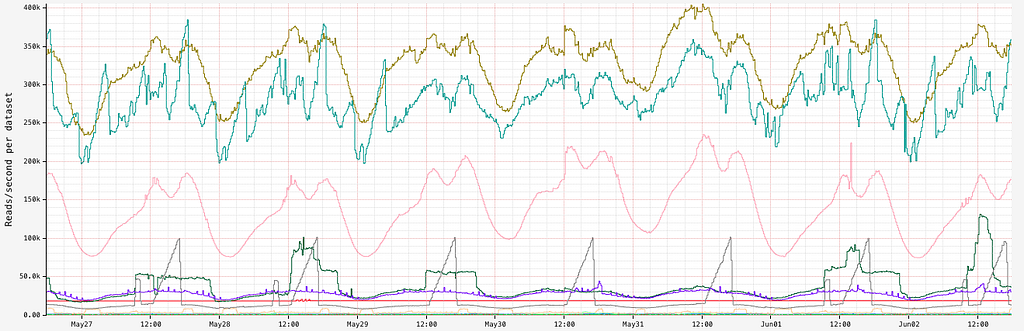
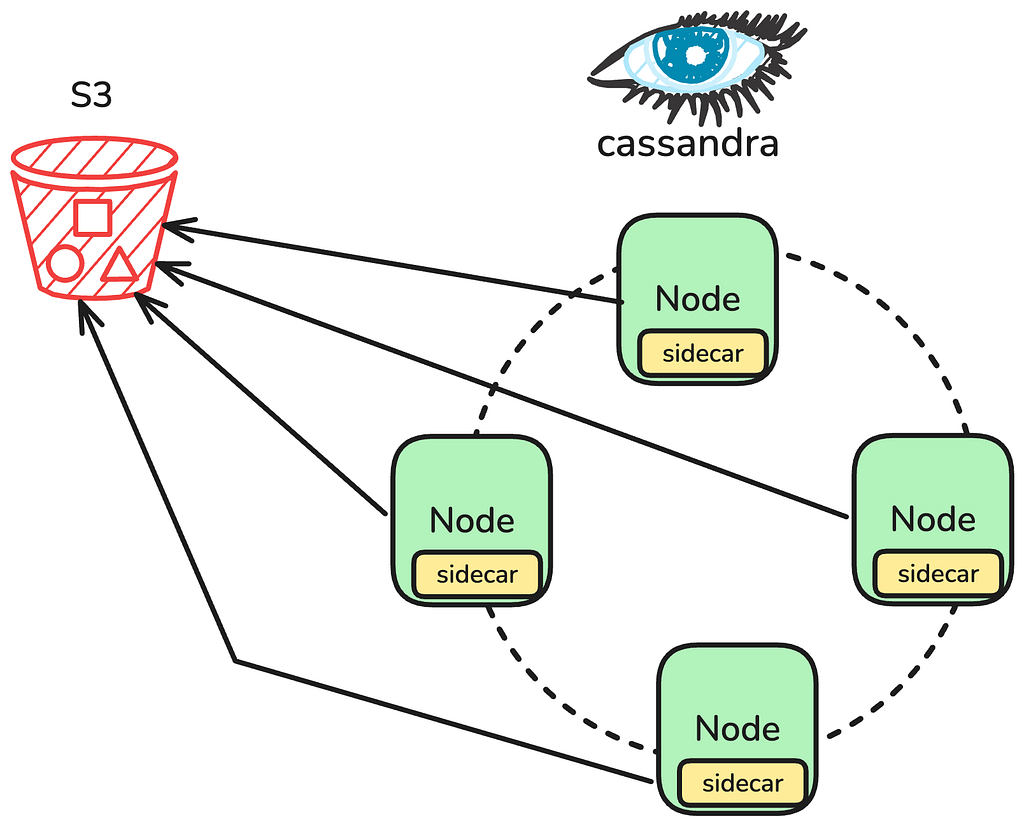
By Rajiv Shringi , Kaidan Fullerton , Oleksii Tkachuk and Kartik Sathyanarayanan Introduction Netflix’s TimeSeries Abstraction is a scalable system for ingesting and querying petabytes of temporal event data with millisecond latency. We use Apache Cassandra 4.x as the underlying storage for these main reasons: Throughput, latency, and cost : Cassandra can handle millions of low‑latency reads and writes in…
29 May

By Oleksii Tkachuk , Kartik Sathyanarayanan , Rajiv Shringi Introduction Netflix has a diverse range of graph use cases, each serving specific business needs with unique functionality and performance requirements. These use cases fall into two broad categories: OLAP : These use cases typically involve open-ended and algorithmic exploration of large graph datasets. They often utilize industry-standard models and languages…

By Parth Jain , Rakesh Sukumar , Yingwu Zhao , Renzo Sanchez & Nathan Fisher How we built a living map of our distributed infrastructure to help engineers understand dependencies, troubleshoot faster, and keep Netflix running smoothly for our members around the world. The Puzzle with a Thousand Pieces Picture this: It’s 3am, and an engineer gets paged. One of…
8 May
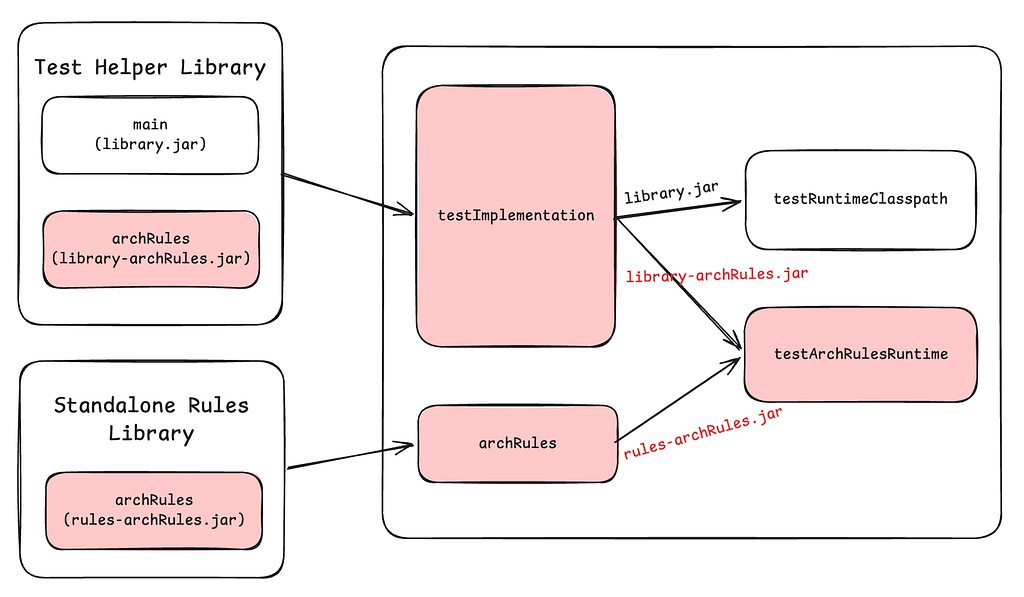
By John Burns and Emily Yuan Introduction At Netflix, we operate using a polyrepo strategy with tens of thousands of Java repositories. This means that we need to have ways of sharing common build logic across these repositories. On the JVM Ecosystem team within Java Platform, we build tooling such as the Nebula suite of Gradle plugins to provide standard…
4 May

Saish Sali , Nipun Kumar , Sura Elamurugu Introduction As Netflix has grown, machine learning continues to support our ability to deliver value to members and drive excellence across multiple areas of our business. When Netflix began investing in machine learning over a decade ago, it was primarily focused on a single domain: personalization. Scala was the industry standard, our…
1 May

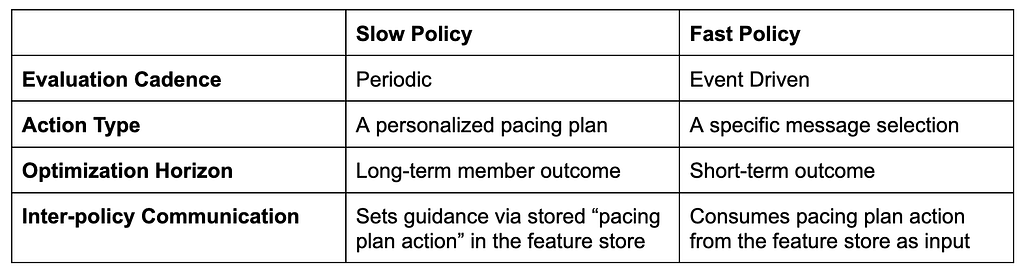
By Nipun Kumar , Rajat Shah , Peter Chng Introduction This is the first blog post in a multi-part series that shares technical insights into how our ML model serving infrastructure powers several personalized experiences at scale across various domains (e.g., title recommendations, commerce). In this introductory blog post, we will dive into our domain-independent API abstraction and its traffic…
24 Apr

Orchestrating Media Workflows Through Strategic Collaboration Authors: Eric Reinecke , Bhanu Srikanth Introduction to Content Hub’s Media Production Suite At Netflix, we want to provide filmmakers with the tools they need to produce content at a global scale, with quick turnaround and choice from an extraordinary variety of cameras, formats, workflows, and collaborators. Every series or film arrives with its…
17 Apr

By: Brett Axler , Casper Choffat , and Alo Lowry In the three years since our first Live show, Chris Rock: Selective Outrage , we have witnessed an incredible expansion of our live content slate and the live operations that support it. From modest beginnings of streaming just one show per month, we are now capable of streaming over nine…
10 Apr

by Gabriela Alessio , Cameron Taylor , and Cameron R. Wolfe Introduction When members log into Netflix, one of the hardest choices is what to watch. The challenge isn’t a lack of options — there are thousands of titles — but finding the most intriguing one is complex and deeply personal. To help, we surface personalized promotional assets , especially…
6 Apr
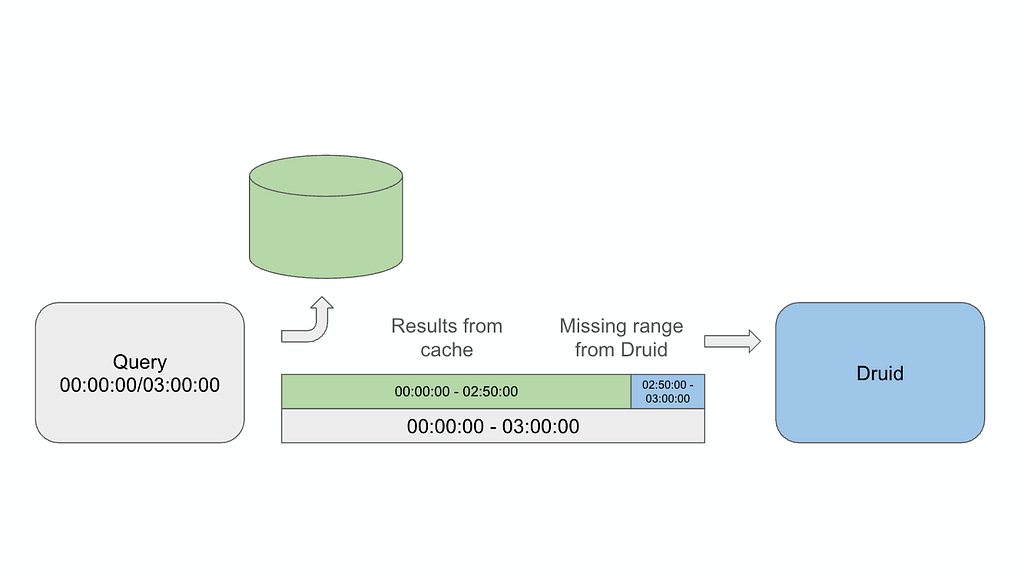
By Ben Sykes In a previous post , we described how Netflix uses Apache Druid to ingest millions of events per second and query trillions of rows, providing the real-time insights needed to ensure a high-quality experience for our members. Since that post, our scale has grown considerably. With our database holding over 10 trillion rows and regularly ingesting up…