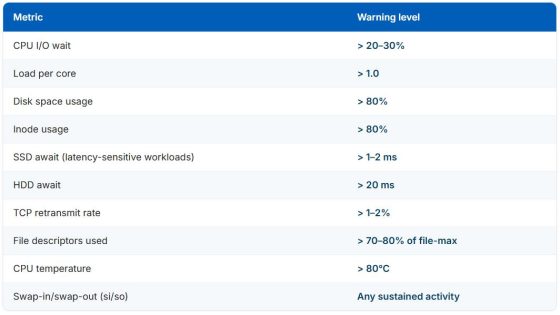
Building Service Topology at Scale: Architecture, Challenges, and Lessons Learned
Netflix Technology BlogBy Parth Jain , Rakesh Sukumar , Yingwu Zhao , Renzo Sanchez-Silva & Nathan Fisher A deep dive into the engineering challenges of building a real-time service dependency map at Netflix scale: from streaming architectures and distributed aggregation pipelines to time-travel queries and the methodology that made it work. Introduction In our first post , we introduced the problem: engineers…