Companies like Spotify need vast quantities of data accessible at low latency for online services and,... The post Indexing the Data Lake for Online Point Queries appeared first on Spotify Engineering.
#infrastructure
48 posts
Yesterday
14 Jul

Training an LLM is the easy part. The hard part is designing experiments and evaluations that you can trust enough to know whether the new model is actually an improvement. By : Baharak Saberidokht Introduction Shipping a production LLM system means iterating fast on improvements to something that is, by construction, non-deterministic. Models drift, judges disagree with themselves, references regenerate…
16 Jun

Next-generation artificial intelligence (AI) and high-performance computing (HPC) chips routinely exceed 1000 W Thermal Design Power (TDP). Simply put, standard air cooling cannot manage these extreme heat loads. The alternative — retrofitting entire data center facilities with chilled water loops — requires extensive amounts of capital and time. To solve this problem, Google developed Brazos, a rack-mounted, closed-loop liquid-to-air cooling…
4 Jun

How Airbnb built a Kubernetes sidecar to deliver dynamic configuration reliably at scale. By : Bo Teng , Cosmo Qiu , Siyuan Zhou , Ankur Soni , Xin Huang , Willis Harvey Introduction In our previous post , we explored Airbnb’s dynamic configuration system, Sitar, with a focus on service architecture and configuration change safety. Now for the harder question:…
1 Jun

We investigated why firmware updates were causing our core servers to take four hours to reboot. By diving into UEFI data structures and iPXE automation, we eliminated unnecessary timeouts and cut boot times back down to minutes.
19 May

How Airbnb shifts from PaaS to an internal knowledge graph infrastructure at scale. By: Lucen Zhao , Shukun Yang , Ashish Jain Knowledge graphs offer a natural and powerful way to represent relationships between entities. Many real-world systems are fundamentally about connections. Airbnb’s identity graph captures relationships between users in a graph database. The identity graph serves aggregated insights that…
5 May

Designing monitoring that works when everything else doesn’t. By : Abdurrahman J. Allawala Introduction When an incident hits, teams lean on observability to answer the only questions that matter: what’s broken, and why? Monitoring systems are designed to help you answer these questions, and they usually do. But what happens when your observability stack is dependent on the same systems…
1 May

By Nipun Kumar , Rajat Shah , Peter Chng Introduction This is the first blog post in a multi-part series that shares technical insights into how our ML model serving infrastructure powers several personalized experiences at scale across various domains (e.g., title recommendations, commerce). In this introductory blog post, we will dive into our domain-independent API abstraction and its traffic…

Guangtong Bai | Staff Software Engineer, Product ML Infrastructure*; Shantam Shorewala | Software Engineer II, Product ML Infrastructure*; Chi Zhang | Staff Software Engineer, AI Platform*; Neha Upadhyay | Software Engineer II, AI Platform*; Haoyang Li | Director, Product ML Infrastructure *These authors contributed equally to this article. Background At Pinterest, our online ML serving systems employ a root-leaf architecture.…
28 Apr

How Airbnb built a lightweight workflow engine to solve durable execution. By : Ricardo Gamba , Andriy Sergiyenko Introduction: The durable execution problem Picture this hypothetical flow: A host submits an insurance claim about their listing to Airbnb. The system needs to validate the claim, run trust and safety checks, assess estimates, process the payout, and send notifications. Halfway through…
21 Apr

How we built a storage system that ingests 50 million samples per second and stores 2.5 petabytes of logical time series data. By : Rishabh Kumar Modern observability practice encourages instrumenting every meaningful code path. Over the past 15 years, open-source observability SDKs like Prometheus, OpenTelemetry, and StatsD have made deep instrumentation nearly ubiquitous. These days, most software — open-source…
20 Apr

Shanhai Liao | Senior Software Engineer, Content Acquisition and Media Platform; Di Ruan, | Senior Staff Software Engineer, Content Acquisition and Media Platform; Evan Li, | Senior Engineering Manager, Content Acquisition and Media Platform Introduction Accurate content understanding underpins Pinterest’s ability to drive distribution and engagement. This requires deep insight not just into the image itself, but also the outbound…
13 Apr

Authors: Matt Lawhon | Sr. Machine Learning Engineer; Filip Ryzner | Machine Learning Engineer II; Kousik Rajesh | Machine Learning Engineer II; Chen Yang | Sr. Staff Machine Learning Engineer; Saurabh Vishwas Joshi | Principal Engineer At Pinterest, scaling our recommendation models delivers outsized impact on the quality of the content we serve to users. Our Foundation Model (oral spotlight,…
7 Apr

A production-tested approach for moving a large-scale metrics pipeline from StatsD to OpenTelemetry and Prometheus. By: Eugene Ma , Natasha Aleksandrova When migrating to a new monitoring system, you’ll want to frontload the work to collect all your metrics. This exposes bottlenecks at full write scale and unblocks the migration of assets which require real data for validation, such as…
2 Apr

By turning compaction into a layered, adaptive pipeline and strengthening our monitoring and controls, we made Magic Pocket more resilient to workload changes.
31 Mar
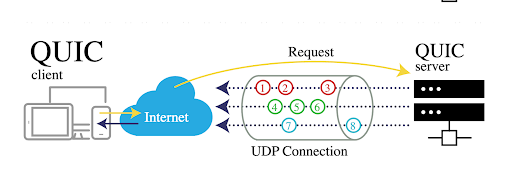
The Problem: Legacy Tooling and Its Limitations Currently, Slack utilizes a hybrid approach to network measurement, incorporating both internal (such as traffic between AWS Availability Zones) and external (monitoring traffic from the public internet into Slack’s infrastructure) solutions. These tools comprise a combination of commercial SaaS offerings and custom-built network testing solutions developed by our…
25 Mar

Monorepos will continue to grow as products evolve, but growth doesn’t have to mean friction.
12 Jan

A deep dive into the technical challenges of keeping .NET's product repositories synchronized with our Virtual Monolithic Repository using a custom two-way algorithm. The post How We Synchronize .NET’s Virtual Monorepo appeared first on .NET Blog.
20 Nov 2025

An exploration of how .NET evolved from a distributed build system to Unified Build, dramatically reducing complexity and build times while improving flexibility and predictability for shipping .NET releases. The post Reinventing how .NET Builds and Ships (Again) appeared first on .NET Blog.
19 Jun 2025

In the fast-paced world of engineering, the dream of easy infrastructure management and provisioning is a common aspiration. At Zendesk, this sentiment resonates deeply among our engineers. When we talk about infrastructure, we refer to a wide range of tools such as MySQL, S3, DynamoDB, Kafka topics, compute resources, network and routing configurations, security groups, secrets, credentials, configuration settings, dashboards,…
20 Dec 2024

An incident report for the Canva outage on November 12, 2024.
10 Oct 2024
We’ve been working to bring components of Quip’s technology into Slack with the canvas feature, while also maintaining the stand-alone Quip product. Quip’s backend, which powers both Quip and canvas, is written in Python. This is the story of a tricky bug we encountered last July and the lessons we learned along the way about…
17 Sept 2024

At Slack, we manage tens of thousands of EC2 instances that host a variety of services, including our Vitess databases, Kubernetes workers, and various components of the Slack application. The majority of these instances run on some version of Ubuntu, while a portion operates on Amazon Linux. With such a vast infrastructure, the critical question…
18 Apr 2024
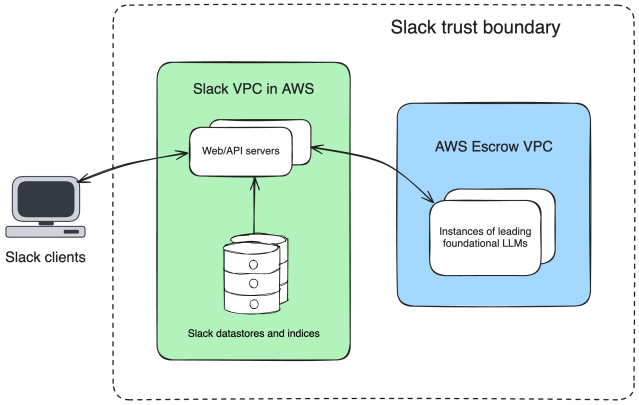
At Slack, we’ve long been conservative technologists. In other words, when we invest in leveraging a new category of infrastructure, we do it rigorously. We’ve done this since we debuted machine learning-powered features in 2016, and we’ve developed a robust process and skilled team in the space. Despite that, over the past year we’ve been…
12 Dec 2023
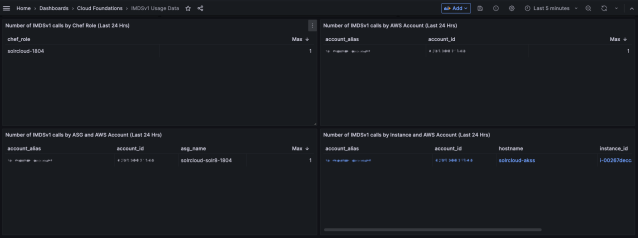
We are heavy users of Amazon Compute Compute Cloud (EC2) at Slack — we run approximately 60,000 EC2 instances across 17 AWS regions while operating hundreds of AWS accounts. A multitude of teams own and manage our various instances. The Instance Metadata Service (IMDS) is an on-instance component that can be used to gain an…
28 Nov 2023

Slack Connect, AKA shared channels, allows communication between different Slack workspaces, via channels shared by participating organizations. Slack Connect has existed for a few years now, and the sheer volume of channels and external connections has increased significantly since the launch. The increased volume introduced scaling problems, but also highlighted that not all external connections…
28 Sept 2023
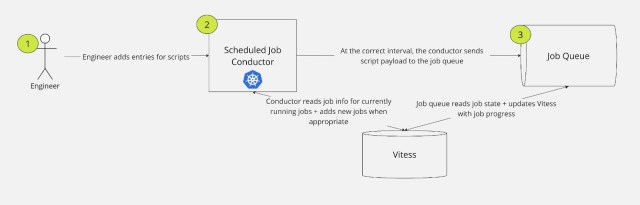
Cron scripts are responsible for critical Slack functionality. They ensure reminders execute on time, email notifications are sent, and databases are cleaned up, among other things. Over the years, both the number of cron scripts and the amount of data these scripts process have increased. While generally these cron scripts executed as expected, over time…
28 Aug 2023
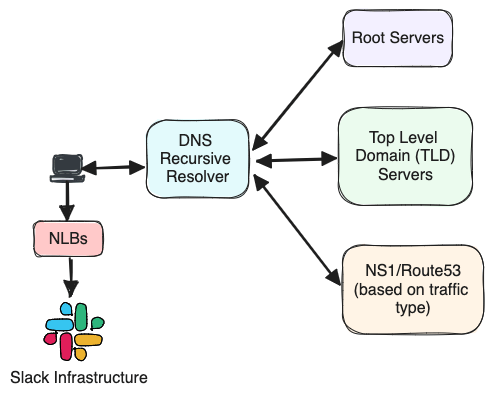
Slack handles billions of inbound network requests per day, all of which traverse through our edge network and ingress load balancing tiers. In this blog post, we’ll talk about how a request flows — from a Slack’s user perspective — across the vast ether of the network to reach AWS and then Slack’s internal…
22 Aug 2023
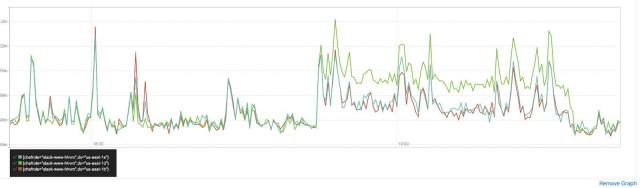
Summary In recent years, cellular architectures have become increasingly popular for large online services as a way to increase redundancy and limit the blast radius of site failures. In pursuit of these goals, we have migrated the most critical user-facing services at Slack from a monolithic to a cell-based architecture over the last 1.5 years.…
28 Jun 2023

It’s not just developers who rely on APIs. DevOps engineers and data engineers also use APIs for many reasons, including to manage cloud infrastructure. For example, you can programmatically manage resources, configure services, and perform operations using APIs. Let’s review other reasons to use cloud APIs. Reasons to use cloud APIs In addition to providing a management console and SDKs,…
11 Apr 2023
Did you know that ground stations transmit signals to satellites 22,236 miles above the equator in geostationary orbits, and that those signals are then beamed down to the entire North American subcontinent? Satellite radios today serve hundreds of channels across 9,540,000 square miles. Unless you’re working at a secret military facility, deep underground, you can…
21 Mar 2023
This blog post discusses the strategies that Slack uses to manage the lifecycle (development, support, and eventual retirement) of infrastructure projects, through the lens of the migration through three successive internal “platform” offerings. Our challenges Circa 2020, our Cloud Engineering team (now evolved into multiple teams responsible for narrower aspects) was responsible for managing our…
24 Jan 2023

Slack launched GovSlack in July 2022. With GovSlack, government agencies, and those they work with, can enable their teams to seamlessly collaborate in their digital headquarters, while keeping security and compliance at the forefront. Using GovSlack includes the following benefits: Supports key government security standards, such as FedRAMP High, DoD IL4, and ITAR Runs in…
25 Oct 2022

At Slack, we use Terraform for managing our Infrastructure, which runs on AWS, DigitalOcean, NS1, and GCP. Even though most of our infrastructure is running on AWS, we have chosen to use Terraform as opposed to using an AWS-native service such as CloudFormation so that we can use a single tool across all of our…
6 Sept 2022

Slack, as a product, presents many opportunities for recommendation, where we can make suggestions to simplify the user experience and make it more delightful. Each one seems like a terrific use case for machine learning, but it isn’t realistic for us to create a bespoke solution for each. Instead, we developed a unified framework we…
29 Aug 2022
A second update on our Gitea migration. It's short in text, but contains a set of 10 videos recorded on the 10th of August.
19 Aug 2022
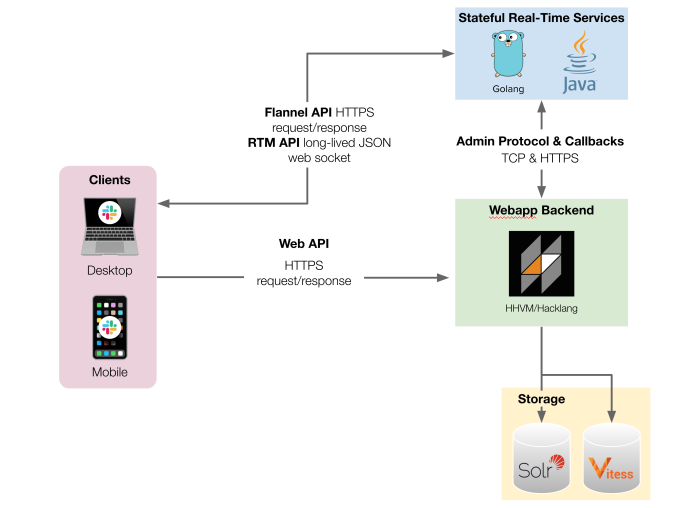
What happens when your distributed service has challenges with stampeding herds of internal requests? How do you prevent cascading failures between internal services? How might you re-architect your workflows when naive horizontal or vertical scaling reaches their respective limits? These were the challenges facing Slack engineers during their day-to-day development workflows in 2020. Multiple internal…
12 Jul 2022
First installment of a series about moving Blender’s development from Phabricator to Gitea.
9 Mar 2022
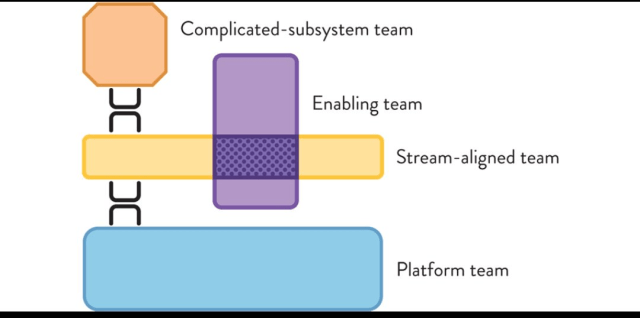
According to a recent Thoughtworks radar, “the industry is increasingly gaining experience with platform engineering product teams that create and support internal platforms.” They caveated this with a piece of advice: “When creating a platform, it’s critical to have clearly defined customers and products that will benefit from it rather than building in a vacuum.”…
20 Oct 2021

About a year ago, I wrote a blog post called Building the Next Evolution of Cloud Networks at Slack. In it, we discussed how Slack’s AWS infrastructure has evolved over the years and the pain points that drove us to spin up a brand-new network architecture redesign project called Whitecastle. If you have not had…
7 Oct 2021

Slack is an integral part of where work happens for teams across the world, and our work in the Core Development Engineering department supports engineers throughout Slack that develop, build, test, and release high-quality services to Slack’s customers. In this article, we share how teams at Slack evolved our internal tooling and made infrastructure bets.…
28 Jul 2021
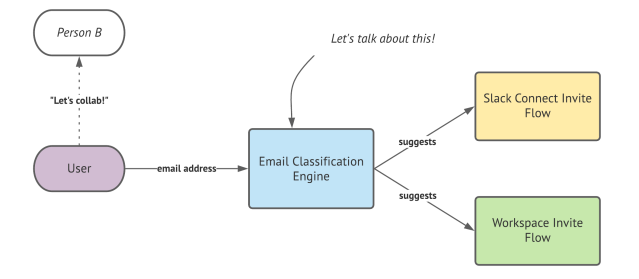
With the release of Slack Connect, people can now collaborate both with internal employees and external organizations in the same channel. To make this as smooth as possible, Slack does predictive email analysis to classify and recommend the best way for a user to work with people they want to collaborate with. To accomplish this,…
22 Jan 2019

At Small Improvements, we are always keen to learn about our customers and how we can make the product better for them. Speaking to customers is great (and we do it all the time) but using the data we hold to find trends and usage patterns helps to find things that the customer won’t tell […]
20 Oct 2017
Whalecome to this blog post 🐳. I want to share with you how we use Docker at Small Improvements, how it helps us to get our everyday tasks done and what we learned from working with it. For starters, I added an introductory section about what Docker actually is – if you are already familiar with […]
12 Sept 2016

It’s no secret that we at Small Improvements love to use cutting edge technologies for our application. On the client side, there’s no limit, that’s why we’re rapidly transitioning to React. In the backend, we’re pushing the limits too, but we’re currently bound by what the App Engine has to offer. The main grievance for us is that […]
27 Jan 2014
Our SaaS application is built with Java, managed with Gradle and runs on Google App Engine. That makes a surprisingly lean and agile combination. Since we do like to work with the best tools available the folks responsible for the back-end love IntelliJ IDE. So of course we utilize the IntelliJ plugin for Gradle. It’s amazingly simple to […]
22 Jun 2013
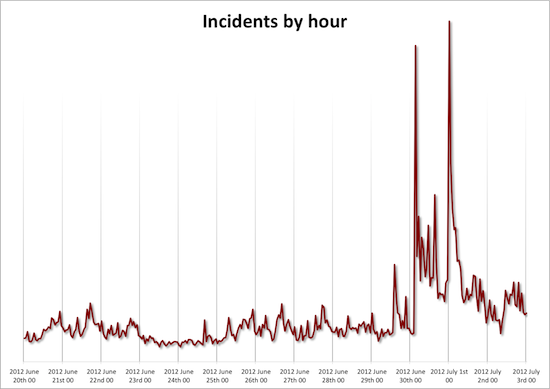
Greetings all! In the world of SaaS, wiser men than I have referred to Operations as the “Secret Sauce” that distinguishes you from your competition. As manager of one of our DevOps teams, I wanted to talk to you about how Bazaarvoice uses the cloud and how we engineer our systems for maximum reliability. You […]
19 Dec 2012
I recently did a presentation at the Berlin Java User Group, during which I summarised the past two years that we’ve been operating Small Improvements on the Google App Engine platform. Some things went great, others not so much. Here are the slides (German only) [slideshare id=15704136&w=510&h=410&sc=no]